OpenAI重磅发现:让Transformer“瘦身”99.9%,电路可解释性暴增16倍!

大语言模型(LLM)的能力日益强大,但其内部工作机制却像一个难以捉摸的“黑箱”,这让无数研究者头疼不已。我们真的能彻底理解Transformer内部的算法吗?最近,OpenAI的一项研究为我们带来了曙光。他们没有选择在复杂的密集模型上“事后”解释,而是另辟蹊径:从头训练一个绝大部分权重都为零的“稀疏”模型。结果惊人:这些模型不仅性能不俗,其内部形成的神经回路(circuits)更是小到可以被人类完全理解,为我们打开了窥探AI心智的全新窗口。
ArXiv URL:http://arxiv.org/abs/2511.13653v1
核心思想:用权重稀疏换取可解释性
这项研究的核心思想非常直接:通过强制模型在训练时将绝大多数权重参数设为零,即约束权重的 $L_0$ 范数,来构建权重稀疏(weight-sparse)的Transformer。
在这些模型中,一个神经元只能与少数几个其他神经元连接。这种“极简主义”的设计哲学,迫使模型学习更解耦、更高效的表征方式,而不是将概念分散在网络的各个角落。
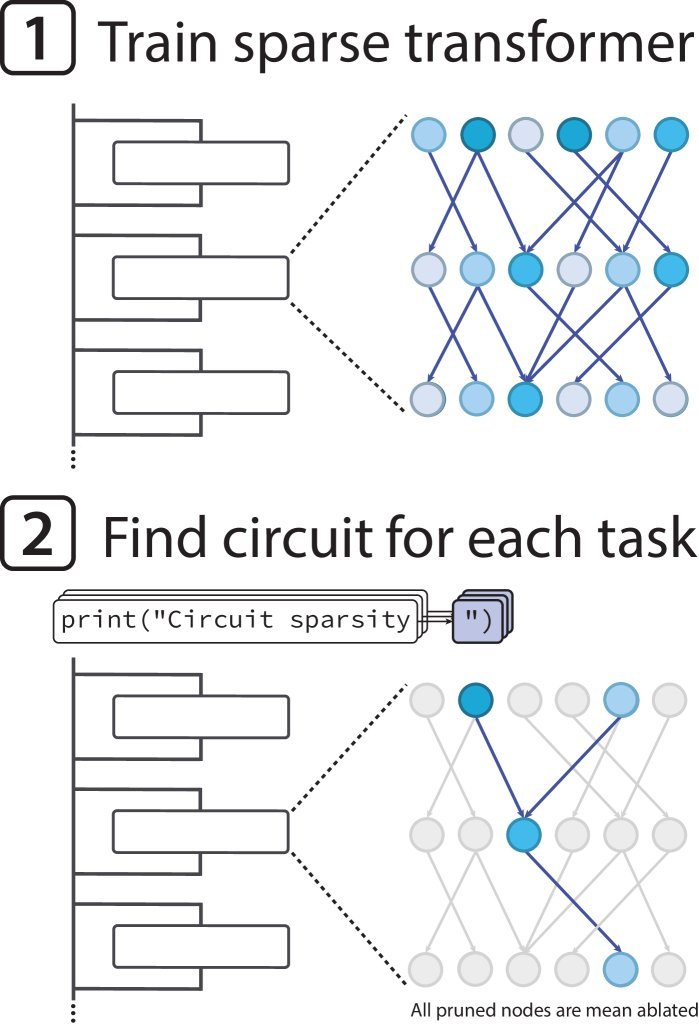
研究的整体流程如下图所示:
-
从头开始训练一个权重稀疏的Transformer模型。
-
针对一系列精心设计的简单任务(如补全代码),对模型进行“剪枝”,分离出执行该任务所需的最小化神经回路。
-
分析这些被分离出来的、极其精简的电路。
稀疏模型:电路规模缩小16倍
稀疏化真的能带来更好的可解释性吗?答案是肯定的。
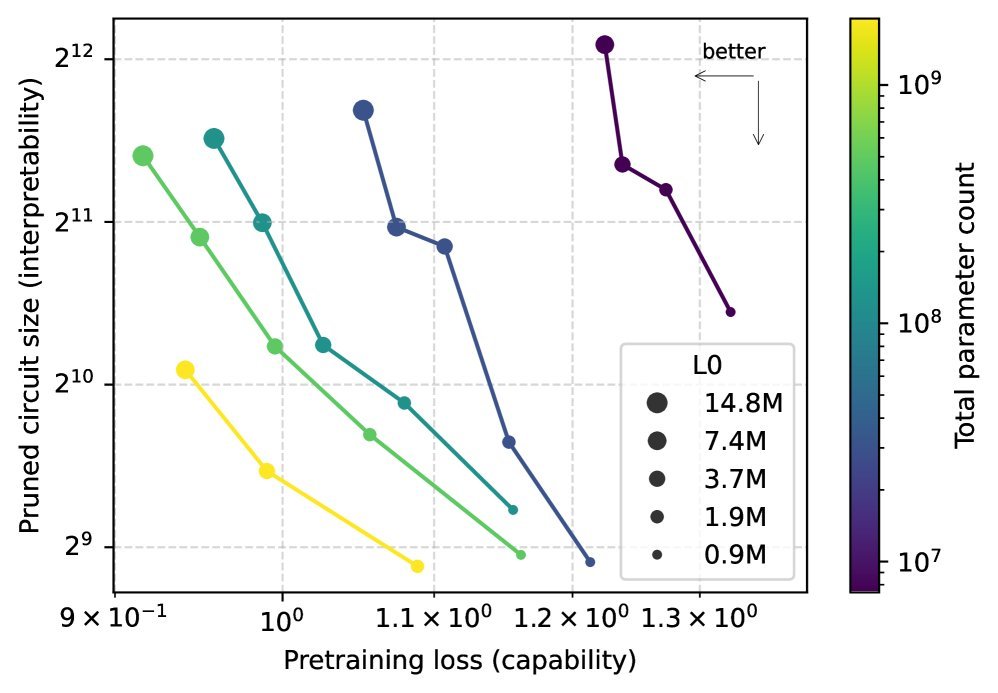
研究人员对比了一个稀疏模型和一个与之预训练损失相当的密集模型。结果发现,在完成相同任务的前提下,从稀疏模型中提取出的神经回路,比密集模型中的小了大约16倍!

这表明,在权重稀疏模型中,特定行为的实现机制更加局部化和解耦,这为我们手动分析它们提供了极大的便利。
当然,天下没有免费的午餐。研究也揭示了模型能力与可解释性之间的权衡关系。在总参数量固定的情况下,模型越稀疏,可解释性越好,但性能会有所下降。好消息是,通过扩大模型规模,可以同时提升性能和可解释性,推动“帕累托前沿”不断向更优的方向发展。
电路解剖:AI如何“思考”?
这篇论文最激动人心的部分,莫过于对具体任务电路的“庖丁解牛”。研究者们手动分析了几个任务的电路,其清晰程度前所未有。
案例一:闭合字符串引号
这是一个简单的任务:模型需要根据开头的引号(单引号或双引号)来补全相应的闭合引号。
研究发现,模型完成这个任务的电路极其简洁,仅涉及1个MLP层中的2个神经元和1个注意力头。整个过程清晰可见,总共只用了9条连接边!
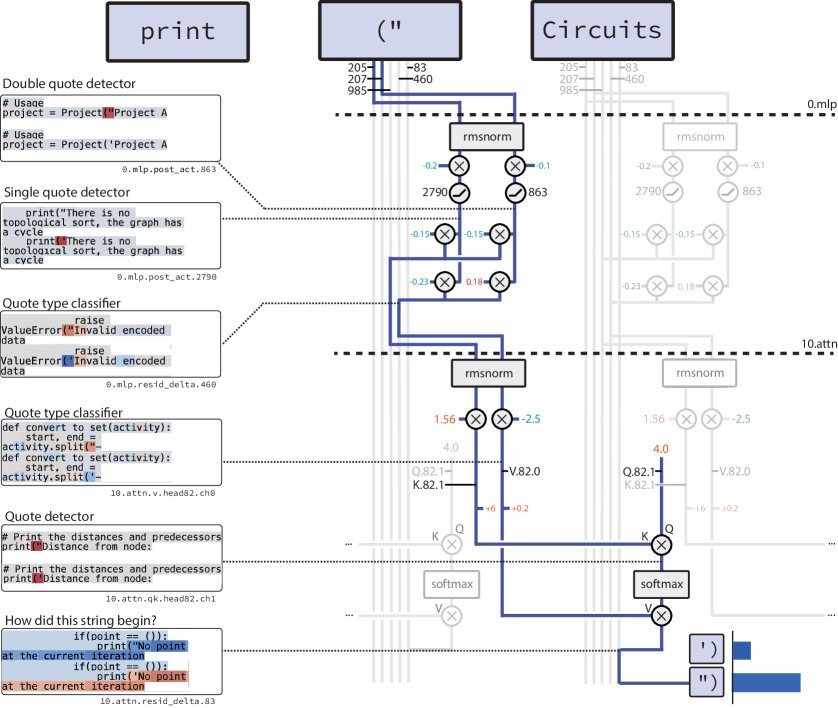
上图完整展示了这个电路的全部细节:
-
检测与分类:MLP层的神经元首先将输入的引号Token转换为“引号检测器”和“引号类型分类器”两种信号,并写入残差流。
-
信息复制:后续的注意力头读取这些信号,一个通道作为Key,另一个作为Value。当需要闭合引号时,注意力机制会找到开头的引号,并将其“类型”信息复制到当前位置,从而预测出正确的闭合引号。
这个电路逻辑清晰,几乎就像是人类程序员会写下的算法。
案例二:计算列表嵌套深度
另一个更复杂的任务是判断列表的嵌套深度,以决定是用 \(]\) (单层)还是 \(]]\) (嵌套)来闭合。
模型学会了一种巧妙的“平均池化”算法:
-
括号检测:模型首先通过词嵌入将 \([\) 符号标记为“括号检测器”。
-
深度计数:一个特殊的注意力头(Head 125)的Query几乎为零,而Key在所有位置上都是常数。这使得注意力softmax操作近似于对上下文中的“括号检测器”信号进行平均。这个平均值的大小,就编码了列表的嵌套深度。
-
阈值判断:另一个注意力头(Head 80)利用这个“深度”值作为Query,通过与一个固定的“注意力池”(attention sink)比较,实现阈值判断。当深度足够大时,它才会激活并输出 \(]]\)。
这个电路的发现还带来了一个意外收获:它揭示了模型的一个弱点。由于该机制依赖于对整个上下文取平均,当上下文变得非常长时,深度的信号会被“稀释”,导致模型在长列表上犯错。这个通过电路分析发现的对抗性攻击,甚至在同等能力的密集模型上也有效!
从稀疏到密集:搭建理解的“桥梁”
尽管从头训练稀疏模型在可解释性上取得了巨大成功,但它们在计算上极其低效,难以扩展到前沿模型。那么,我们能否利用这种方法来理解现有的、强大的密集模型呢?
研究团队提出了一个初步的解决方案:桥接(Bridges)。他们训练一个稀疏模型,同时在每一层都建立一个“桥梁”,负责在稀疏模型和目标密集模型的激活值之间进行双向转换。
这个稀疏模型就像一个可解释的“代理”,它学习模仿密集模型的计算过程。通过操纵稀疏模型中某个可理解的神经元,并观察其通过“桥梁”对密集模型输出的影响,研究者可以验证他们对密集模型内部机制的假设。初步实验表明,这种方法确实能够部分地编辑密集模型的表征,为理解现有大模型提供了新的可能。
局限与展望
这项工作无疑是机制可解释性(Mechanistic Interpretability)领域的一大步,但前路依然漫长。
最主要的挑战是计算效率。稀疏模型的训练和推理成本比同等性能的密集模型高出100-1000倍。此外,多义性特征(polysemantic features)问题虽然得到缓解,但并未完全消除。
尽管如此,这项研究为我们指明了方向。通过引入像权重稀疏这样的归纳偏置,我们能够训练出本质上更易于理解的模型。这些清晰的、可验证的神经回路,不仅让我们离“解剖”AI心智的目标更近了一步,也为未来的自动化可解释性研究提供了更简洁、更强大的分析原语。或许,彻底揭开大模型黑箱的那一天,已经不远了。