What Affects the Effective Depth of Large Language Models?
MIT新发现:大模型半数层在“划水”,R1推理变强竟不靠深度?

在大模型(LLM)的Scaling Law竞赛中,我们似乎达成了一个共识:模型越深,能力越强。为了追求更高的智能,模型层数从几十层堆叠到上百层。然而,来自麻省理工学院(MIT)和北京大学的一项最新研究却给这股“堆层数”的热潮泼了一盆冷水。
ArXiv URL:http://arxiv.org/abs/2512.14064v1
这项研究提出了一个直击灵魂的问题:那些动辄上百层的庞然大物,真的每一层都在进行复杂的计算吗?还是说,它们只是在机械地重复劳动?
该研究通过深入分析Qwen-2.5系列和DeepSeek-R1蒸馏版模型,揭示了一个令人惊讶的真相:现代大模型存在严重的“深度利用率”问题,即便是以推理能力著称的长思维链(Long-CoT)模型,其变强的原因也并非“思考得更深”,而是另有玄机。
什么是“有效深度”?
在深入实验之前,我们需要理解论文的核心概念——有效深度(Effective Depth)。
先前的研究已经发现,大模型的层级并不是平等的。通常,模型的前半部分层负责构建特征(Feature Composition),而后半部分层往往只是在对已有特征进行微小的修补(Refinement)。
如果把大模型比作一个画师,前半程他在构图、上色、勾勒细节(这是“有效”的计算);而后半程,他可能只是拿着放大镜在画面上擦擦灰尘、调调光影(这是“无效”或低效的计算)。
该研究基于Qwen-2.5家族(1.5B到32B)和DeepSeek-R1蒸馏版,试图解开三个谜题:模型规模、训练方式(如CoT)和任务难度,究竟谁能改变这个“有效深度”?
谜题一:模型越大,利用率越高吗?
直觉告诉我们,更大的模型应该更聪明,对深度的利用应该更充分。但研究结果却恰恰相反。
研究人员使用余弦相似度(Residual Cosine Similarity)等工具探测了Qwen-2.5系列模型。结果发现,随着模型参数量的增加(从1.5B到32B),虽然“有效层”的绝对数量增加了,但有效深度在总层数中的比例却保持惊人的稳定。
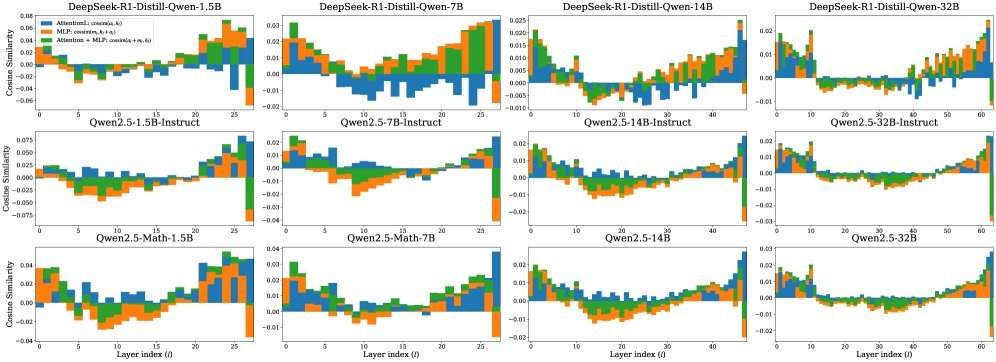
图1:GSM8K任务上的余弦相似度分析。可以看到,所有模型都呈现出相似的趋势:在中间某处发生相变,之后相似度回升,意味着后续层级贡献递减。
这意味着,更大的模型并没有学会“新”的计算策略,它们只是把小模型的计算模式简单粗暴地拉长了。大模型变强,是因为它变得更“宽”了(获得了新能力),而在深度上,它只是在做更精细的微调,而非更深层次的推理。
谜题二:DeepSeek-R1 变强是因为“想得更深”吗?
这是本论文最引人注目的发现。
近期,像DeepSeek-R1和OpenAI o1这样的长思维链(Long-CoT)模型在复杂推理任务上大放异彩。人们普遍假设:这些模型之所以强,是因为它们在每一个Token的生成过程中,利用了更深层的网络进行逻辑推演。
为了验证这一点,研究者对比了Qwen-2.5基座模型与其对应的DeepSeek-R1蒸馏版(即经过Long-CoT训练的模型)。
结果令人大跌眼镜:两者的有效深度几乎没有区别。
这说明了什么?这说明Long-CoT模型推理能力的提升,并不是源于在单个Token生成时挖掘了更深的网络层级,而是源于更长的上下文序列。
换句话说,模型变聪明不是因为它在“脑子”(神经网络深度)里转得更深了,而是因为它学会了在“草稿纸”(Context)上写下更多的步骤。推理的本质是“广度”(序列长度)的胜利,而非“深度”(层数利用)的胜利。
谜题三:遇到难题,模型会“全力以赴”吗?
最后一个问题关于动态适应性。如果给模型一道简单的小学数学题(GSM8K)和一道复杂的奥数题(AIME24),模型会自动调用更多的层级来处理难题吗?
研究显示:完全不会。
无论是在简单的文本理解任务(HellaSwag),还是在极难的数学竞赛任务中,模型的有效深度分布几乎是一条直线。模型并没有展现出“遇强则强”的动态调节能力,它在处理难题时,依然保留了大量的“摸鱼”层级。
总结与启示
这项研究揭示了当前大模型架构的一个根本性低效:无论规模多大、训练多精良、任务多困难,模型都未能充分利用其深度。
这为未来的研究指明了几个极具潜力的方向:
-
模型剪枝(Pruning):既然后半程很多层都在“划水”,我们是否可以大刀阔斧地砍掉它们,而不影响性能?
-
提前退出(Early Exiting):对于简单样本,模型是否可以在中间层就直接输出结果,从而大幅节省算力?
-
提升利用率:如何设计新的架构,强迫模型在深层网络中进行真正的“特征合成”,而不是简单的“修修补补”?
DeepSeek-R1等模型的成功证明了通过拉长推理序列可以绕过深度利用率的瓶颈,但如何真正激活那沉睡的一半神经网络,或许才是通往下一代更高效AI的关键钥匙。