What Does Loss Optimization Actually Teach, If Anything? Knowledge Dynamics in Continual Pre-training of LLMs
Loss一直降,模型却没学会?揭秘LLM持续预训练的“学习假象”

在大模型训练的常识中,有一个根深蒂固的信仰:Loss(损失函数)是真理。我们默认只要 Loss 曲线平滑下降,模型就在稳步变强,新的知识就在被“吸收”。
ArXiv URL:http://arxiv.org/abs/2601.03858v1
但如果我告诉你,这可能是一个巨大的错觉呢?
来自特伦托大学(University of Trento)的研究团队抛出了一项颠覆性的研究。他们发现,在持续预训练(Continual Pre-Training, CPT)过程中,Loss 的下降往往掩盖了模型内部剧烈的动荡:事实知识的学习极不稳定,刚学会的知识转头就忘,甚至连原本的数学和推理能力也会随之崩塌。
这篇论文像是一记警钟,敲醒了盲目追求低 Loss 的炼丹师们:优化(Optimization)不等于学习(Learning)。
核心问题:Loss 真的能代表知识习得吗?
在 LLM 的生命周期中,为了让模型掌握最新的事实(比如“2024年谁是美国总统”),我们通常会进行持续预训练(CPT)。目前的标准做法是:喂入新数据,观察 Next-Token Prediction 的 Loss,Loss 降了,我们就认为模型学会了。
然而,这种做法有一个巨大的盲区:它只看结果,不看过程。
为了揭开这个黑盒,研究团队设计了一个精妙的实验框架:
-
构建受控数据集:利用维基百科的修订历史,构建了一个分布完全匹配(Distribution-Matched)的数据集。这意味着模型读到的文本风格和预训练时一模一样,唯独事实性知识(Fact)变了。
-
Epoch 级别的“探针”:他们没有只看训练结束后的 Checkpoint,而是在每一个 Epoch 结束时,都把探针插进模型里,实时监测:
-
新知识学会了吗?(Acquisition)
-
旧知识忘了吗?(Retention)
-
其他能力(如数学、逻辑)坏了吗?(OOD Skills)
-
惊人发现一:Loss 骗了你,学习曲线是“过山车”
实验结果令人大跌眼镜。
如下图所示,在 OLMo-7B 模型的训练过程中,困惑度(PPL)(蓝线)如预期的那样单调下降,看起来一切都很完美。
但是,代表事实召回率(Factual Recall)(橙线)的曲线却像过山车一样剧烈震荡!模型在某个 Epoch 学会了新知识,下一个 Epoch 可能就忘了,接着又重新学会。
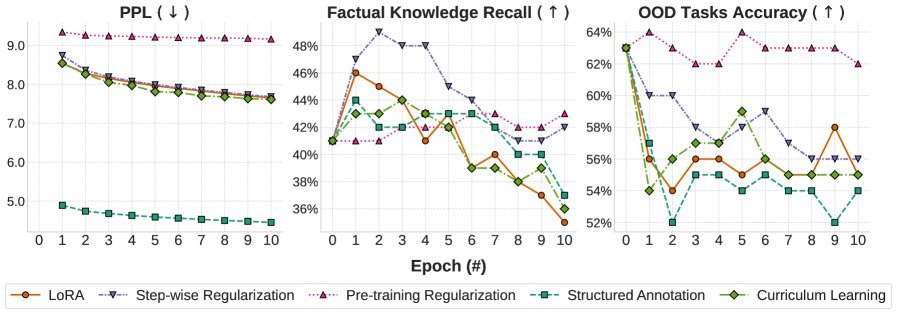
这意味着什么?
这意味着 Loss 的降低并不代表知识被稳固地“存入”了模型的参数中。优化过程和真正的学习过程发生了系统性的背离。你以为模型在稳步进步,实际上它可能正在经历“学了忘,忘了学”的死循环。
惊人发现二:高频词“赢家通吃”,低频词“无人问津”
研究进一步分析了不同实体的学习动态,发现了一个残酷的现实:模型极其势利。
-
高频实体(High-Frequency Entities):模型对这些常见的概念(如著名城市、大人物)表现出强烈的学习波动,虽然不稳定,但至少在尝试学。
-
低频实体(Low-Frequency Entities):对于那些冷门的知识,模型几乎完全学不进去。无论你训练多少个 Epoch,召回率始终在低位徘徊。
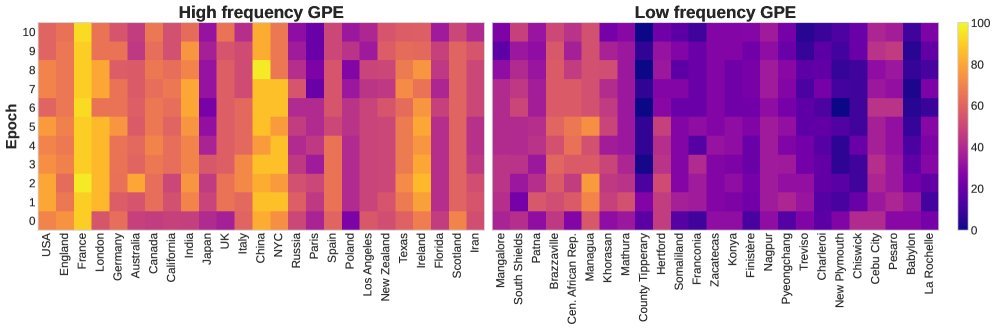
如上图所示,低频实体(左侧)的召回率几乎是一条死线。这说明,如果你的新知识不够“热门”,仅仅通过 CPT 灌输,模型很可能根本记不住。
惊人发现三:捡了芝麻,丢了西瓜
更糟糕的消息是关于域外能力(Out-Of-Domain, OOD)的。
我们希望模型在学习新知识的同时,不要变笨。但实验表明,几乎所有的 CPT 策略(无论是 LoRA、结构化标注,还是课程学习),都会导致 OOD 能力(如数学 MMLU、社会推理 SocialIQA)的即刻下降。
回到图 1,看那条绿色的线(OOD Tasks Accuracy),它几乎是从训练开始的那一刻起就开始单调下滑。为了学会几个新事实,模型牺牲了通用的推理能力。 唯一起作用的是 KL 散度正则化(Pre-training Regularization),它确实保住了 OOD 能力,但代价是——模型也几乎学不会任何新知识了。
深度追问:多训练一会就好了?
有人可能会说:“是不是训练时间不够长?多跑几个 Epoch 让他巩固一下?”
研究者做了这个实验:让 LLaMA-1B 在干净的数据上跑了整整 100 个 Epoch。
结果是灾难性的(见下图):
-
Loss 早就收敛躺平了。
-
事实召回率在第 5 个 Epoch 达到峰值,然后一路崩盘,跌到一个低水平的震荡区间。
-
OOD 能力更是直接腰斩,再也没恢复。
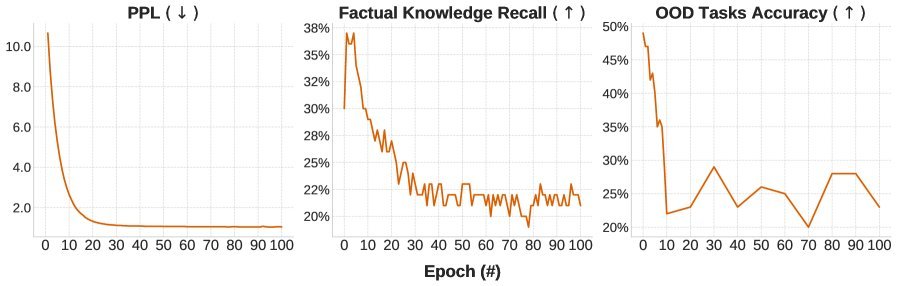
这证明了“大力出奇迹”在 CPT 场景下是行不通的。随着训练的进行,模型并没有巩固知识,而是在不断地覆写(Overwriting)。
机制揭秘:知识回路的疯狂重组
为了搞清楚模型内部到底发生了什么,研究者使用了知识回路(Knowledge Circuits)分析技术。他们追踪了模型内部负责输出正确答案的神经元连接(Edges)。
结果发现,随着 Epoch 的推移,负责同一个知识点的“电路”在不断地剧烈重组。
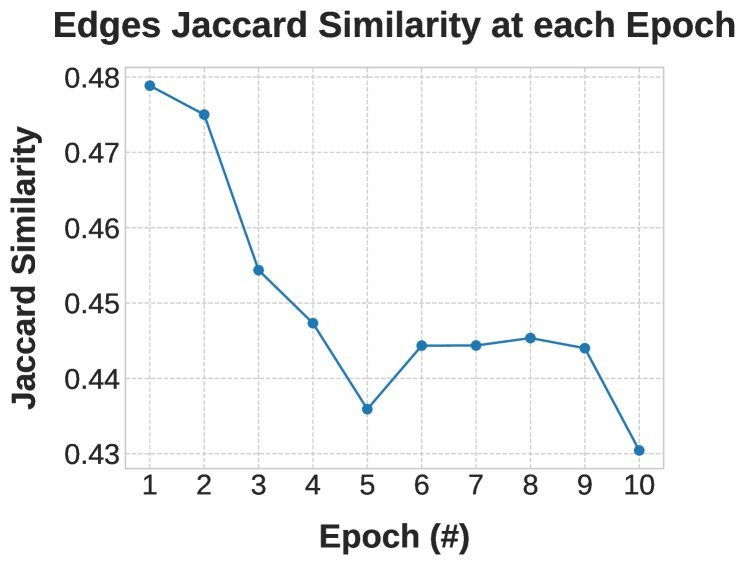
上图展示了不同 Epoch 之间知识回路的 Jaccard 相似度。可以看到,相似度极低。这意味着,模型并不是在强化某一条通路来记忆知识,而是每次都在寻找新的、临时的通路来“过拟合”当前的数据。这种不稳定的内部表征,正是导致“学了就忘”的根本原因。
总结与启示
这篇论文给当前火热的 LLM 训练泼了一盆冷水,但也指明了方向:
-
Loss 具有欺骗性:在持续预训练中,不要盲目相信 Loss。你需要基于任务级别的指标(如事实探针)来决定何时停止训练。
-
RAG 可能是更好的选择:研究者对比了 检索增强生成(Retrieval-Augmented Generation, RAG),发现 RAG 在事实召回上轻松碾压了所有 CPT 策略。如果你只是想让模型知道“新知识”,外挂知识库可能比改参数更靠谱。
-
优化 $\neq$ 学习:我们需要重新思考 LLM 的学习机制。目前的梯度下降优化,似乎更擅长“拟合模式”,而不是“存储事实”。
下次当你看到模型 Loss 终于降下来时,先别急着开香槟,也许它刚刚把最重要的数学能力给忘光了。