When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models
少即是多?8-bit量化竟让大模型持续学习能力暴涨15%

在人工智能领域,我们通常认为“精度即正义”:模型参数的精度越高(如FP16),性能就越好;而量化(Quantization)通常被视为一种为了节省计算资源而不得不做出的妥协,往往伴随着性能的损失。
ArXiv URL:http://arxiv.org/abs/2512.18934v1
但如果我告诉你,在持续学习(Continual Learning)的场景下,这个常识被彻底颠覆了呢?
最新的研究发现,低精度的量化模型(如8-bit)在学习新任务时,反而比高精度模型更能记住旧知识,甚至在某些任务上性能翻倍! 这不仅是一个技术上的反直觉发现,更为我们在资源受限设备上部署能“终身学习”的AI提供了全新的思路。
本文将带你深入解读这篇名为《When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models》的论文,揭秘量化噪音如何成为对抗“灾难性遗忘”的神奇解药。
核心挑战:灾难性遗忘
大语言模型(LLM)虽然强大,但它们有一个致命弱点:记性不好。当你用新数据微调一个已经训练好的模型时,它往往会迅速忘记之前学过的东西,这种现象被称为灾难性遗忘(Catastrophic Forgetting)。
为了解决这个问题,研究人员通常使用经验回放(Replay Buffer)策略,即在训练新任务时,混入少量旧任务的数据。
然而,现实部署中我们面临着双重约束:
-
计算资源限制:我们需要对模型进行量化(如从FP16降到INT4)以减少显存占用。
-
存储资源限制:我们不能无限期地保存大量旧数据,回放缓冲区(Buffer)必须尽可能小。
那么问题来了:量化精度与回放缓冲区大小之间,究竟存在怎样的博弈关系?
惊人的反转:量化反而更强?
Algoverse的研究团队在LLaMA-3.1-8B模型上进行了一系列严谨的实验。他们让模型按顺序学习三类任务:自然语言理解(NLU)、数学推理(Math)和代码生成(Code)。
实验结果令人大跌眼镜:
-
初始表现:不出所料,FP16(高精度)模型在刚开始的任务上表现最好。
-
持续学习后的反转:随着任务不断增加,FP16模型的表现开始崩塌。相反,量化模型(INT8和INT4)展现出了惊人的韧性。在最终任务的前向准确率上,量化模型比FP16高出了8-15%。
-
代码生成的奇迹:在代码生成任务中,INT4模型的表现竟然达到了FP16的两倍(40% vs 20%)。
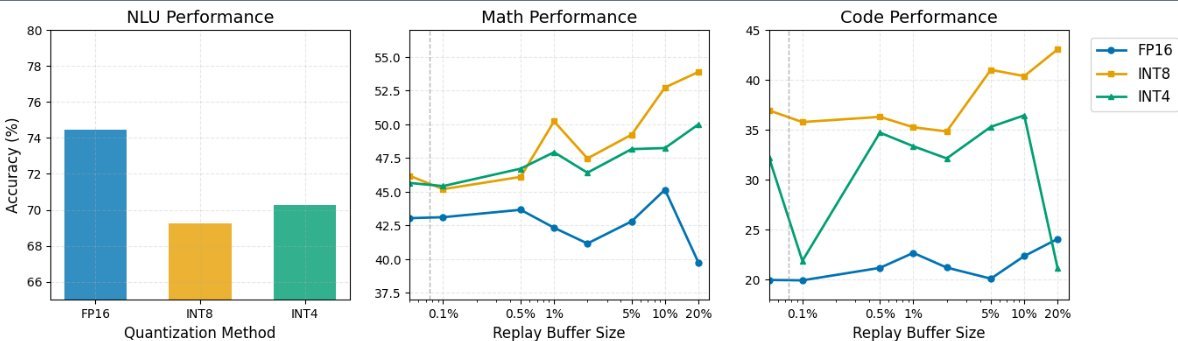
图1:不同量化精度与回放大小下的任务表现。可以看到在低回放比例下,量化模型(特别是INT8)表现出了优越的稳定性。
为什么“少”即是“多”?
为什么精度低的模型反而学得更好、忘得更少?论文提出了一个非常有趣的假设:量化引入的噪音充当了隐式正则化(Implicit Regularization)的角色。
这就好比我们在学习时,如果记得太死(过拟合),遇到新问题就容易钻牛角尖,把旧知识丢掉。
-
FP16模型:太“聪明”且敏感,容易对新任务的梯度过拟合,导致旧知识被迅速覆盖。
-
量化模型(INT8/INT4):由于精度的损失,引入了随机噪音。这些噪音平滑了损失函数的曲面,迫使模型找到更平坦、更通用的极小值点。
这种机制使得量化模型在面对极少量的回放数据(甚至只有0.1%)时,也能有效地锚定旧知识,实现了学习可塑性(Plasticity)与记忆保持性(Retention)的最佳平衡。
实验洞察:INT8是黄金平衡点
研究者通过构建“量化-回放权衡图”,得出了一些极具实战价值的结论:
-
INT8是最佳选择:它在计算效率和持续学习动力学之间取得了完美的平衡。相比之下,INT4虽然在某些极端情况下表现出色,但对回放缓冲区的大小非常敏感,如果Buffer太小,性能会断崖式下跌。
-
极小回放也有大作用:对于量化模型,仅仅保留0.1%的旧数据,就能让NLU任务的保留率从45%飙升到65%。
-
FP16的脆弱性:高精度模型在缺乏足够回放数据时,遗忘速度最快。这意味着如果你必须使用FP16,你反而需要更大的存储空间来保存旧数据。
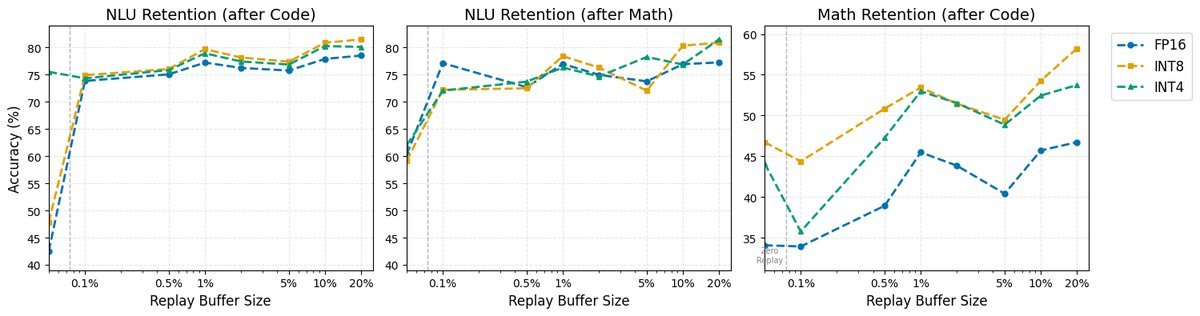
图2:不同精度下的知识保留率。注意看INT8在低回放比例下的稳健表现。
部署建议:如何配置你的模型?
基于上述发现,论文为实际部署提供了具体的参数建议:
-
自然语言任务(NLU):无论是哪种精度,1-2%的小型回放缓冲区就足够了。
-
数学与代码任务:这类任务更难保留。
-
如果你用INT8/INT4:建议分配5-10%的缓冲区。
-
如果你用FP16:为了达到同样的保留效果,你可能需要10-20%甚至更大的缓冲区。
-
总结
这项研究打破了我们对模型压缩的刻板印象。量化不仅仅是为了省钱省显存,它在持续学习的动态过程中,竟然还能意外地充当“护身符”,防止模型喜新厌旧。
对于正在开发端侧AI或需要频繁更新模型知识的开发者来说,这无疑是一个巨大的好消息:拥抱8-bit量化,你可能不仅获得了速度,还收获了更持久的记忆。