You Need Better Attention Priors
斯坦福GOAT:重构注意力底层数学,显存降36%,长文本性能全面超越RoPE

Transformer 架构统治 AI 领域已久,但你是否想过,其核心组件——缩放点积注意力(Scaled Dot-Product Attention),可能建立在一个“天真”的假设之上?
ArXiv URL:http://arxiv.org/abs/2601.15380v1
长期以来,我们将 Softmax 视为一种平滑的 Argmax 近似,将点积视为相似度度量。然而,斯坦福大学的一项最新研究指出,这种直觉式的理解掩盖了数学本质。该研究通过熵最优传输(Entropic Optimal Transport, EOT)的视角重新审视注意力机制,揭示了一个惊人的事实:标准的注意力机制其实隐含了一个“均匀分布先验”。换句话说,模型默认假设所有 Token 在初始状态下是等价的,这限制了模型的表达能力和长文本外推能力。
为了打破这一限制,研究团队提出了 GOAT(Generalized Optimal transport Attention with Trainable priors),一种带有可训练先验的通用最优传输注意力机制。它不仅在数学上更优雅,完美解释并解决了“注意力黑洞”(Attention Sinks)问题,还在长文本检索和生物序列建模中全面超越了 RoPE 和 ALiBi,甚至在特定任务中将峰值显存降低了 36%。
注意力机制的数学重构:从均匀到可学习
在深入 GOAT 之前,我们需要先理解该研究的核心理论突破。
传统的注意力权重计算通常被视为一种启发式设计。但如果从 EOT 的视角来看,注意力权重 $\mathbf{p}^{\star}$ 实际上是一个传输成本最小化问题的解。在这个问题中,我们需要将 Query 的“质量”分配给各个 Key,成本由点积得分定义,同时为了保持分布的“不确定性”,引入了香农熵作为正则项。
该研究指出,香农熵正则化等价于最小化与均匀分布(Uniform Distribution)的 KL 散度。这意味着,标准注意力机制被迫在“匹配内容得分”和“保持均匀分布”之间做权衡。
为什么必须是均匀的? 斯坦福的研究者认为,我们完全可以用一个更符合数据特性的、可学习的先验分布 $\mathbf{\pi}$ 来替代均匀分布。根据推导,引入任意先验 $\mathbf{\pi}$ 后的最优注意力分布形式非常简洁:
\[\mathbf{p}^{\star}=\mathrm{softmax}\!\big(\mathbf{s}/\tau+\log\mathbf{\pi}\big)\]这里 $\mathbf{s}$ 是未缩放的点积得分。这个公式揭示了注意力机制缺失的一环:对数先验(Log-Prior)应该作为一个加性项,直接作用于 Logits。
这不仅为位置编码(Positional Encoding)提供了坚实的理论基础(位置编码本质上就是一种先验),也解释了为什么像 ALiBi 这样直接加在 Logits 上的偏置往往比旋转位置编码(RoPE)更具鲁棒性。
GOAT:高效、解耦且兼容 FlashAttention
理论很美,但如何高效实现?如果直接学习一个 $L \times L$ 的先验矩阵,计算量和显存都会爆炸。
GOAT 的设计精髓在于其参数化方式。它并没有引入沉重的偏置矩阵,而是通过将 Query 和 Key 向量分解为“内容子空间”和“位置/结构子空间”来实现。

具体来说,GOAT 将 Head Dimension 切分为两部分:
-
内容部分:负责语义匹配,保留了标准注意力的特性。
-
先验部分:包含用于捕捉相对位置关系的谱分量(Spectral Components)和用于捕捉全局默认行为的 Sink 分量。
这种设计使得 GOAT 能够在一个标准的点积操作中同时完成内容匹配和先验计算。最关键的是,GOAT 完全兼容 FlashAttention。它不需要修改底层的注意力 Kernel,也不需要物化巨大的偏置矩阵,保持了极高的计算效率。
完美解释并解决“注意力黑洞”
在大模型中,我们经常观察到一个奇怪的现象:注意力黑洞(Attention Sinks)。即模型倾向于将大量注意力分配给第一个 Token(或其他特定 Token),即使它在语义上并不重要。
现有的解释通常认为这是 Softmax 机制的副作用。但 EOT 理论给出了更本质的解释:当 Query 的语义信号微弱(低信噪比)时,KL 正则项会主导目标函数,迫使注意力分布坍缩回先验分布。
如果先验是均匀的,模型就会不知所措;为了维持稳定性,模型被迫“劫持”部分内容通道,人为制造出高范数的 Key 来充当“锚点”。这实际上污染了语义表示。
GOAT 通过在先验中显式引入一个Sink 项(Key-only bias),优雅地解决了这个问题。
\[\langle\mathbf{q}\_{\text{sink},i},\mathbf{k}\_{\text{sink},j}\rangle=u(j)\]这意味着模型可以在先验层面学习到一个“默认选项”(比如指向特定的 Sink Token)。当语义信息不足时,模型会自动回退到这个默认选项,而无需扭曲内容向量。这实现了结构与语义的完美解耦。
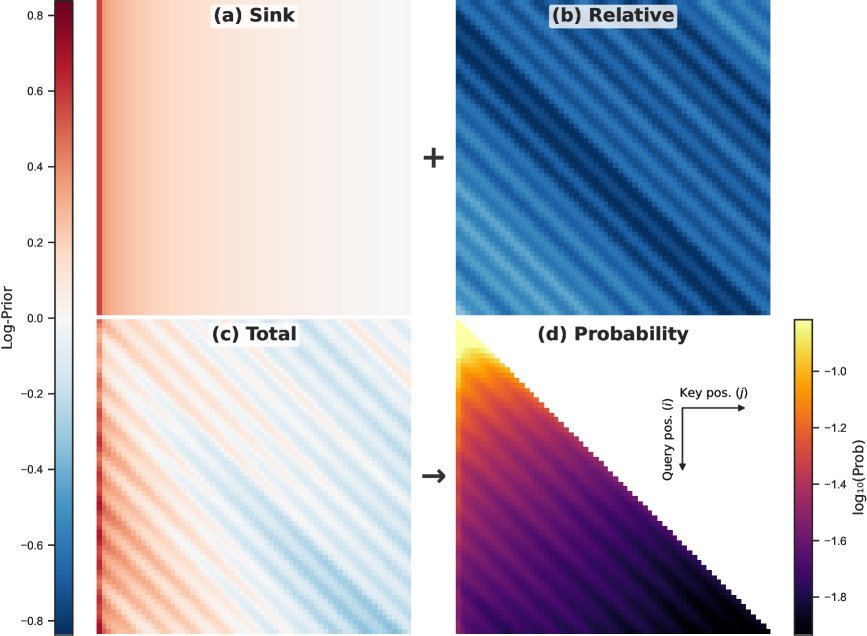
图1:GOAT 在合成任务上学习到的先验分解。(a) 显示了 Sink 组件,(b) 显示了相对位置组件,(c) 是总的 Log-Prior。可以看到 GOAT 自动学会了关注特定位置和相对对角线。
实验结果:长文本与显存的双重胜利
GOAT 的表现如何?研究团队在多个任务上进行了验证。
1. 长文本外推能力爆表
在“大海捞针”(Needle-in-a-Haystack)和 Passkey 检索任务中,GOAT 展现了惊人的长文本泛化能力。即使在推理长度远超训练长度的情况下,GOAT 依然能保持近乎完美的准确率,而 RoPE 和线性插值方法则出现了严重的性能衰退。
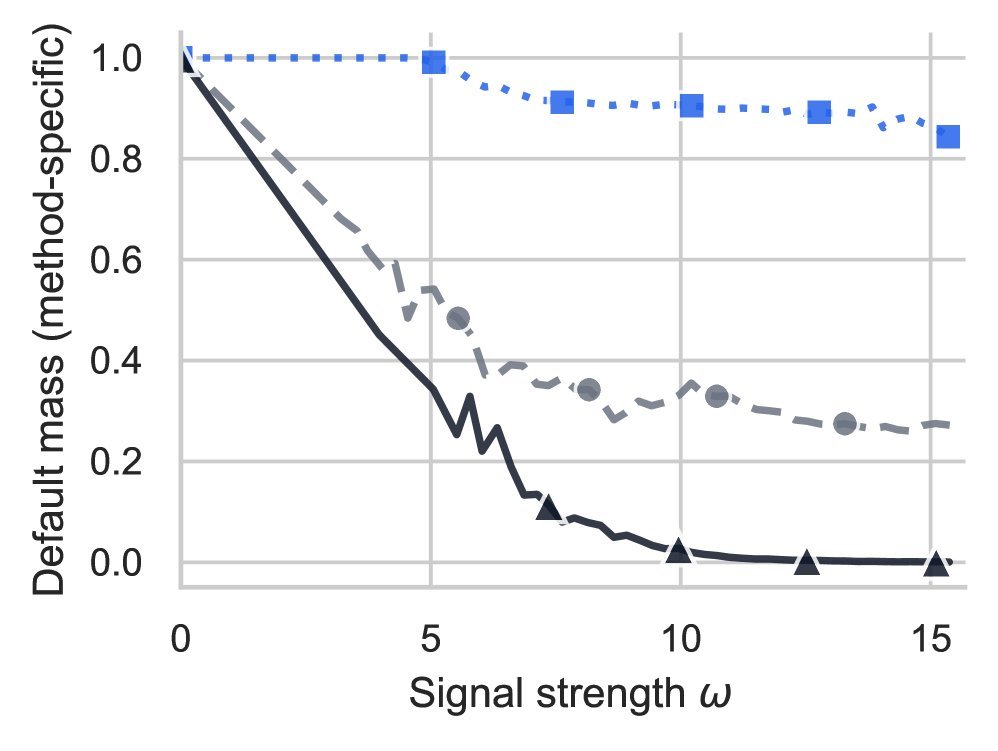
图3(c):大海捞针测试热力图。随着上下文长度增加(横轴)和针的深度变化(纵轴),GOAT(左一)始终保持深红色(高准确率),而 RoPE(左二)等基线方法在长文本下迅速崩溃。
2. 显存占用大幅降低
在基因组序列建模任务中,GOAT 不仅在验证集 NLL(负对数似然)上优于 RoPE,更令人印象深刻的是其资源效率。由于不需要像 RoPE 那样进行复杂的旋转计算,且结构更加紧凑,GOAT 将峰值 CUDA 显存从 2.86 GB 降低到了 1.83 GB,降幅高达 36%。
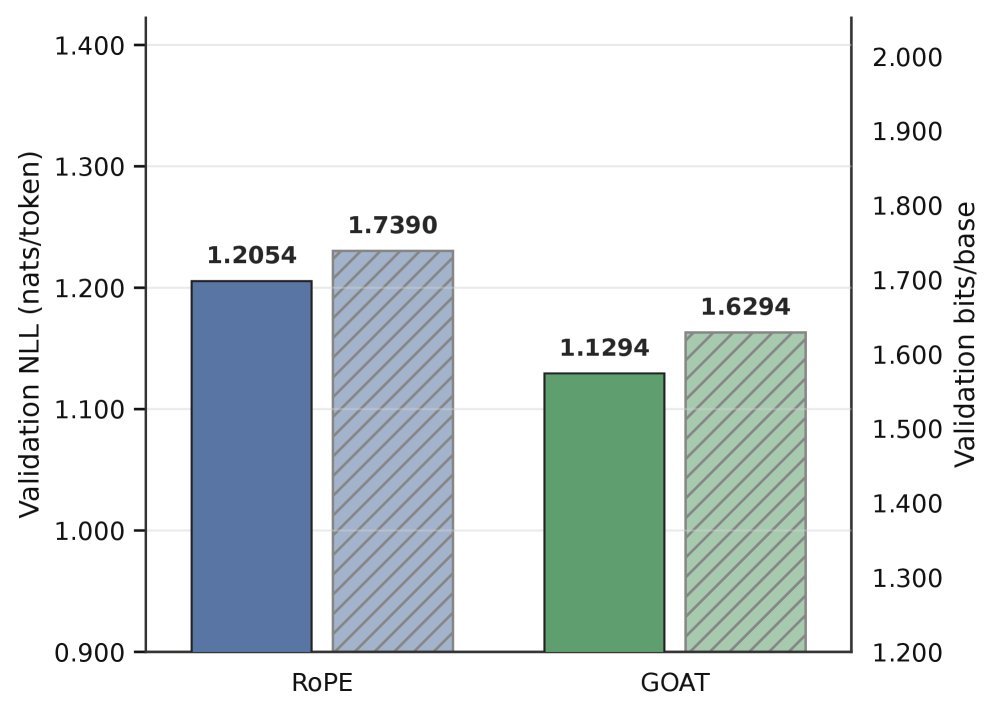
图4(b):在 DNA 建模任务中,GOAT(右侧阴影柱)相比 RoPE(左侧阴影柱)显著降低了峰值显存占用。
总结
GOAT 不仅仅是一个新的注意力变体,它是一次对 Transformer 底层数学假设的成功修正。通过引入 EOT 视角,GOAT 将位置编码、注意力黑洞和长文本外推统一到了同一个数学框架下。
它告诉我们:你需要的不仅仅是更大的窗口,而是更好的先验。
对于正在构建长上下文模型或追求极致推理效率的开发者来说,GOAT 提供了一个极具潜力的替代方案——它既保留了 FlashAttention 的速度,又拥有超越 RoPE 的外推能力,同时还顺手解决了困扰已久的 Attention Sink 问题。这或许就是下一代大模型的标准配置。