Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
腾讯Youtu-LLM重磅发布:1.96B小模型解锁原生Agent能力,128k长文本与11T数据揭秘
在当今的大模型竞赛中,人们往往默认“智能涌现”是千亿参数巨型模型的专利。对于运行在端侧的小于20亿参数(sub-2B)的模型,业界的普遍做法是“蒸馏”——让小模型模仿大模型的输出。但这种方法往往只学到了皮毛,却难以获得真正的推理和规划能力。
ArXiv URL:http://arxiv.org/abs/2512.24618v1
如果一个小模型从出生开始,就是为了成为Agent而设计的呢?
腾讯优图实验室带来的 Youtu-LLM 打破了这一刻板印象。这款仅有1.96B参数的模型,不依赖蒸馏,而是通过从头开始的系统性预训练,在轻量级的身躯内解锁了原生的 Agent 能力。它不仅支持128k超长上下文,更在多项Agent基准测试中超越了同量级SOTA,甚至能够叫板更大规模的模型。
本文将带你深入解读 Youtu-LLM 背后的技术魔法:它是如何通过独特的架构设计和高达11T Token的“课程表”式训练,实现小模型逆袭的?
1. 架构设计:轻量级也能“长考”
对于端侧模型而言,内存和计算效率是首要考量,但Agent任务又极度依赖长上下文来维持状态和记忆。Youtu-LLM 如何平衡这对矛盾?
密集多潜伏注意力(Dense MLA)
Youtu-LLM 并没有采用常见的 混合专家(MoE)架构,因为在端侧场景下,MoE频繁的I/O操作反而可能拖慢速度。相反,该研究采用了 密集多潜伏注意力(Dense Multi-Latent Attention, MLA)机制。
MLA 通过对 KV Cache 进行低秩压缩,并使用更大的中间投影矩阵,在极大地降低显存占用的同时,提升了注意力机制的表达能力。这使得 Youtu-LLM 能够在一个紧凑的内存足迹内,支持长达 128k 的上下文窗口。
专为STEM定制的Tokenizer
除了架构,词表(Vocabulary)也是关键。Youtu-LLM 重新设计了一个面向 STEM(科学、技术、工程、数学)的 Tokenizer。相比 Llama3 的分词器,新设计在处理代码和数学公式时压缩率更高,这意味着同样长度的序列能承载更多的信息密度。
2. 训练策略:从常识到Agent的进阶之路
Youtu-LLM 的核心理念是:Agent能力应当在预训练阶段就注入,而非仅仅靠后期微调。 为此,研究团队构建了一个高达 11T Tokens 的庞大语料库,并设计了一个分阶段的“课程表”。
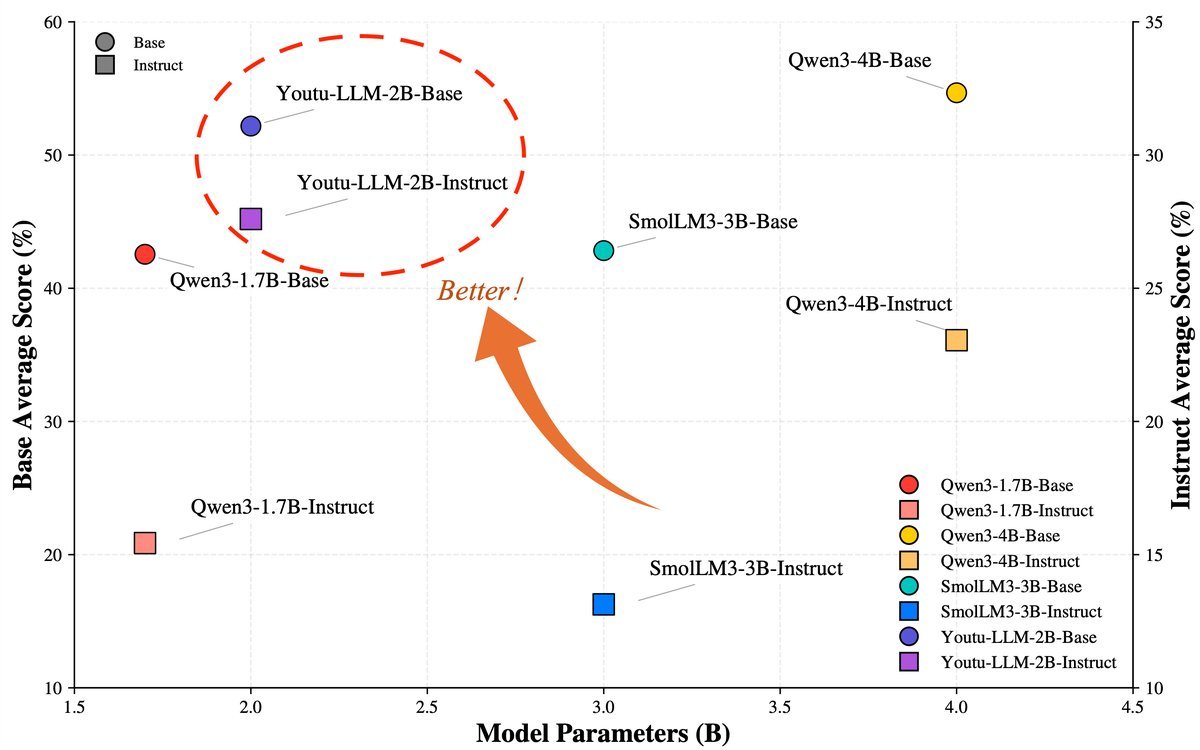
图1:在Agent基准测试中,Youtu-LLM(红色星号)在极小的参数量下展现了惊人的性能,超越了众多同类模型。
阶段式预训练(Multi-stage Pre-training)
这不仅仅是数据的堆砌,而是分布的精心调配:
-
通用基础(Stage 1):使用8.16T数据,主要覆盖网页和百科知识,打好语言基础。
-
STEM强化(Stage 2):将STEM和代码数据的比例大幅提升至60%,强化逻辑推理能力。
-
长文本延展(Stage 3):上下文窗口从8k逐步扩展至128k,让模型学会处理长程依赖。
-
Agent特训(Stage 4):这是最关键的一步。在最后阶段,学习率衰减,而训练数据中有约60%被替换为高质量的 Agent轨迹数据。
3. 核心秘籍:2000亿Token的Agent轨迹
为什么 Youtu-LLM 能像人类一样规划和反思?秘密在于其独特的 Agentic Mid-training 阶段。研究团队合成了约200B Token的高质量轨迹数据,涵盖了数学、代码、深度研究(Deep Research)和工具使用等领域。
这部分数据不再是简单的“问题-答案”对,而是包含了完整的思考过程、工具调用、错误反思和路径修正。
代码Agent轨迹:从单一到分支
为了让模型学会写代码并自我修正,研究者设计了一套可扩展的合成框架(如图5所示)。
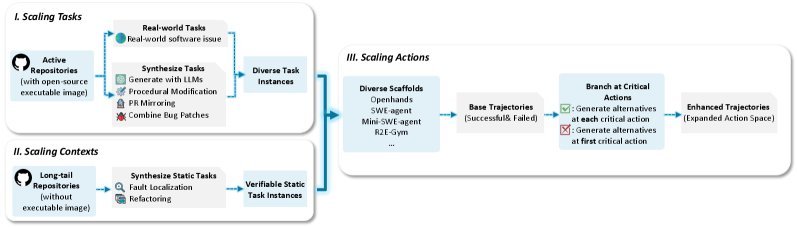
图2:代码轨迹合成流水线。通过扩展任务、上下文和动作分支,构建丰富的执行路径。
该框架不仅生成成功的代码路径,还通过 分支策略(Branching Strategy)保留了失败的尝试和修正过程。这意味着模型在训练时,不仅看到了“正确答案”,还看到了“如何从错误中恢复”,这对于实战中的Agent至关重要。
深度研究(Deep Research):正向与逆向的双重合成
在开放式的深度研究任务中,Agent需要查阅大量资料并生成报告。Youtu-LLM 采用了一种双管齐下的数据合成策略:
-
正向合成:模拟真实的研究流程,规划、搜索、阅读、总结。
-
逆向合成:这是一个巧妙的创新(如图8所示)。研究者从高质量的学术论文或法律文档出发,利用引用关系反向构建搜索路径。既然这篇论文引用了文献A,那么搜索过程就应该指向文献A。这种方法确保了搜索轨迹的真实性和权威性。
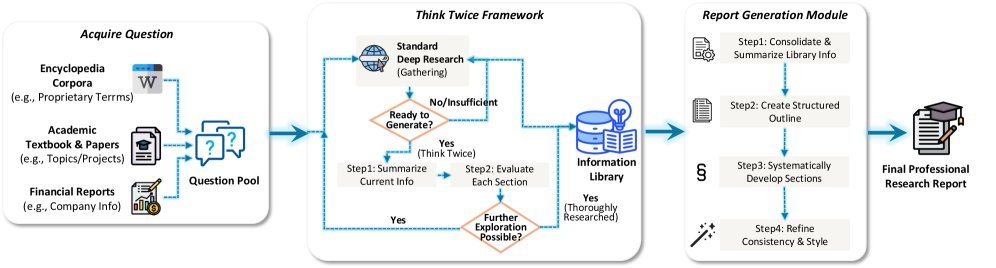
图3:开放式深度研究报告生成的轨迹合成流水线。
4. 实验结果:小身材,大智慧
在通用的基准测试中,Youtu-LLM 展现了均衡的实力。而在其主打的 Agent 领域,优势尤为明显。
-
通用能力:在 MMLU、GSM8K 等榜单上,Youtu-LLM 与 Qwen2.5-1.5B 等优秀模型互有胜负,稳居第一梯队。
-
Agent能力:在涉及工具使用、复杂规划的测试中,Youtu-LLM 显著超越了现有的 sub-2B 模型,甚至在某些指标上能够与更大参数量的模型一较高下。
总结
Youtu-LLM 的出现向社区证明了一个重要结论:轻量级模型的Agent能力不必依赖于对大模型的拙劣模仿。
通过 密集MLA架构 带来的高效长上下文支持,配合 11T Tokens 的分阶段课程学习,特别是引入大规模的 合成Agent轨迹数据 进行预训练,小模型完全可以内化出强大的规划、反思和执行能力。对于希望在端侧设备、移动端应用中部署智能Agent的开发者来说,Youtu-LLM 无疑提供了一个令人兴奋的新选择。